Windows 7でHadoopを動かす方法:分散処理システムの構築手順
HadoopをWindows 7で動かす!分散処理システムの構築 について解説します。この記事では、Windows 7上でHadoopを動かす方法を紹介し、分散処理システムの構築手順を詳しく説明します。Hadoopはオープンソースの分散処理フレームワークであり、大量のデータを高速に処理することができます。
Windows 7でHadoopを動かすためには、まずJava Development Kit (JDK) とHadoopのインストールパッケージをダウンロードし、インストールする必要があります。環境設定では、HadoopのConfigurationファイルを編集し、Hadoopの動作環境を設定します。これらの手順を完了すると、Hadoopを起動し、MapReduceジョブを実行することで、大量のデータを処理することができます。
この記事では、Windows 7でHadoopを動かすための手順を詳しく説明し、分散処理システムの構築方法を紹介します。Hadoopの基本的な概念と動作原理についても解説します。
Hadoopの概要と特徴
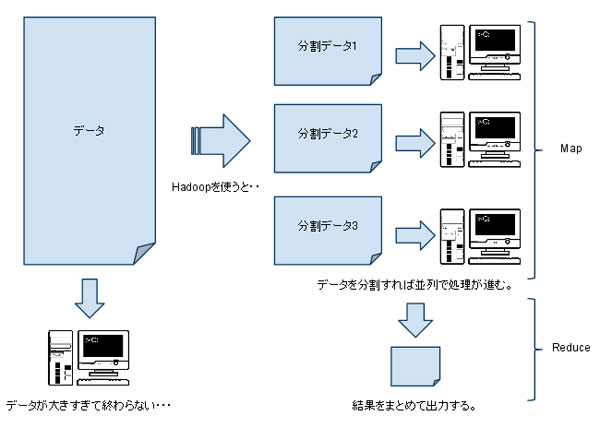
HadoopをWindows 7で動かす!分散処理システムの構築 は、ビッグデータ処理の分野で非常に注目されているテーマです。Hadoopは、オープンソースの分散処理フレームワークであり、大量のデータを高速に処理することができます。Hadoopの特徴は、分散処理システムを構築することで、大量のデータを並列に処理することができることです。
Hadoopは、GoogleのMapReduceを参考に開発された分散処理フレームワークであり、データの処理を分散することで、高速なデータ処理を実現します。Hadoopは、データの格納にHDFS(Hadoop Distributed File System)を使用し、データの処理にMapReduceを使用します。Hadoopは、オープンソースであるため、無料で使用することができ、多くの企業で採用されています。
Hadoopの主な特徴は、スケーラビリティと柔軟性です。Hadoopは、データの量が増加しても、処理速度が低下しないように設計されています。また、Hadoopは、多くのデータ形式をサポートしており、データの処理に柔軟性を提供します。Hadoopは、データの分析や機械学習などの用途に広く使用されています。
Windows 7でHadoopを動かすための環境設定
Windows 7でHadoopを動かすためには、まずJava Development Kit (JDK)をインストールする必要があります。JDKは、Hadoopの動作に必要なJavaランタイム環境を提供します。JDKのインストールが完了したら、Hadoopのインストールパッケージをダウンロードし、インストールする必要があります。
Hadoopのインストールが完了したら、HadoopのConfigurationファイルを編集する必要があります。Configurationファイルでは、Hadoopの動作環境を設定します。たとえば、Hadoopのクラスタの構成、データの保存場所、ジョブの実行方法などを設定します。Configurationファイルを編集することで、Hadoopの動作をカスタマイズすることができます。
HadoopをWindows 7で動かす!分散処理システムの構築には、Hadoopの動作環境を設定するだけでなく、Hadoopのクラスタを構築する必要があります。Hadoopのクラスタは、複数のノードで構成され、各ノードはデータの処理や保存を行います。Hadoopのクラスタを構築することで、大量のデータを高速に処理することができます。
JDKとHadoopのインストール
HadoopをWindows 7で動かす!分散処理システムの構築 には、まずJava Development Kit (JDK) とHadoopのインストールパッケージをダウンロードする必要があります。JDKは、Hadoopの動作に必要なJavaランタイム環境を提供します。Hadoopのインストールパッケージには、Hadoopの分散処理フレームワークが含まれています。
JDKとHadoopのインストールパッケージをダウンロードしたら、インストールを開始します。JDKのインストールは、通常のWindowsアプリケーションのインストールと同様に進められます。Hadoopのインストールパッケージは、zipファイル形式で提供されるため、任意のフォルダに解凍する必要があります。
インストールが完了したら、環境変数を設定する必要があります。環境変数には、JDKとHadoopのインストールフォルダのパスを指定する必要があります。これにより、Hadoopの動作環境が設定され、Hadoopを起動することができます。
HadoopのConfigurationファイルの編集
HadoopをWindows 7で動かす!分散処理システムの構築には、HadoopのConfigurationファイルの編集が必要です。HadoopのConfigurationファイルは、Hadoopの動作環境を設定するために使用されます。Configurationファイルを編集することで、Hadoopの動作をカスタマイズすることができます。
まず、Hadoopのインストールディレクトリに移動し、confディレクトリ内のcore-site.xmlファイルを開きます。このファイルには、Hadoopのコア設定が記述されています。core-site.xmlファイルを編集することで、Hadoopの動作環境を設定することができます。たとえば、Hadoopのデフォルトのポート番号を変更することができます。
次に、mapred-site.xmlファイルを開きます。このファイルには、MapReduceの設定が記述されています。MapReduceは、Hadoopの分散処理フレームワークであり、大量のデータを高速に処理することができます。mapred-site.xmlファイルを編集することで、MapReduceの動作をカスタマイズすることができます。たとえば、MapReduceのデフォルトのジョブ数を変更することができます。
最後に、hdfs-site.xmlファイルを開きます。このファイルには、HDFSの設定が記述されています。HDFSは、Hadoopの分散ファイルシステムであり、大量のデータを格納することができます。hdfs-site.xmlファイルを編集することで、HDFSの動作をカスタマイズすることができます。たとえば、HDFSのデフォルトのブロックサイズを変更することができます。
Hadoopの起動と動作確認
HadoopをWindows 7で動かす!分散処理システムの構築 には、Hadoopの起動と動作確認が不可欠なステップです。Hadoopを起動するには、Command Promptから start-all コマンドを実行する必要があります。このコマンドを実行すると、Hadoopの各コンポーネントが起動し、分散処理システムが構築されます。
Hadoopの起動後、動作確認を行う必要があります。動作確認には、 jps コマンドを使用します。このコマンドを実行すると、Hadoopの各コンポーネントのプロセスIDが表示されます。さらに、 http://localhost:50070 にアクセスすることで、HadoopのWebインターフェイスを確認できます。このインターフェイスから、Hadoopの各コンポーネントの状態を確認することができます。
動作確認が完了したら、MapReduceジョブを実行することで、大量のデータを処理することができます。MapReduceジョブは、 hadoop jar コマンドを使用して実行します。このコマンドを実行すると、MapReduceジョブが実行され、大量のデータが処理されます。
MapReduceジョブの実行とデータ処理
HadoopをWindows 7で動かす!分散処理システムの構築 では、MapReduceジョブの実行が重要なステップです。MapReduceは、Hadoopの分散処理フレームワークの核となるコンポーネントであり、大量のデータを高速に処理することができます。MapReduceジョブを実行することで、データを分散処理し、結果を出力することができます。
MapReduceジョブを実行するには、まず入力データを準備する必要があります。入力データは、Hadoopの分散ファイルシステム(HDFS)に保存する必要があります。次に、MapReduceジョブを定義する必要があります。ジョブ定義には、入力データ、Mapper、Reducer、出力データなどの情報を含める必要があります。
MapReduceジョブを実行するには、Hadoopのコマンドラインインターフェイスを使用する必要があります。コマンドラインインターフェイスから、hadoop jarコマンドを実行し、ジョブ定義ファイルを指定する必要があります。ジョブが実行されると、Hadoopは入力データを分散処理し、結果を出力します。結果は、HDFSに保存されます。
分散処理システムの構築手順
HadoopをWindows 7で動かす!分散処理システムの構築 は、ビッグデータ処理のための重要なステップです。Hadoopは、オープンソースの分散処理フレームワークであり、大量のデータを高速に処理することができます。Windows 7でHadoopを動かすためには、まずJava Development Kit (JDK) とHadoopのインストールパッケージをダウンロードし、インストールする必要があります。
インストールが完了したら、HadoopのConfigurationファイルを編集し、Hadoopの動作環境を設定する必要があります。この設定では、Hadoopのクラスタを構成し、データの保存先を指定することができます。さらに、Hadoopのセキュリティ設定も行う必要があります。
Hadoopの設定が完了したら、Command Promptからstart-allコマンドを実行することで、Hadoopを起動することができます。Hadoopが起動したら、MapReduceジョブを実行することで、大量のデータを処理することができます。分散処理システムを構築することで、大量のデータを高速に処理することができます。
まとめ
HadoopをWindows 7で動かす!分散処理システムの構築 は、ビッグデータ処理のための重要なステップです。Hadoopは、オープンソースの分散処理フレームワークであり、大量のデータを高速に処理することができます。Windows 7でHadoopを動かすためには、Java Development Kit (JDK) とHadoopのインストールパッケージをダウンロードし、インストールする必要があります。
環境設定では、HadoopのConfigurationファイルを編集し、Hadoopの動作環境を設定します。Hadoopを起動するには、Command Promptからstart-allコマンドを実行する必要があります。さらに、MapReduceジョブを実行することで、大量のデータを処理することができます。分散処理システムを構築することで、大量のデータを高速に処理することができます。
この記事では、Windows 7上でHadoopを動かす方法を紹介しました。Hadoopのインストールから環境設定まで、分散処理システムの構築手順を詳しく説明しました。HadoopをWindows 7で動かすことで、ビッグデータ処理のための強力なツールを利用することができます。
よくある質問
Windows 7でHadoopを動かすには何が必要ですか?
Windows 7でHadoopを動かすには、Java Development Kit (JDK) と Cygwin が必要です。JDKはHadoopの動作に必要なJavaランタイムを提供し、CygwinはWindows上でUnix/Linuxコマンドを実行するための環境を提供します。さらに、Hadoopの動作には Hadoop本体 と Windows用バイナリ が必要です。これらのファイルはHadoopの公式サイトからダウンロードできます。
Windows 7でHadoopを動かすための環境設定はどうすればいいですか?
Windows 7でHadoopを動かすための環境設定として、まず システム環境変数 にJDKとHadoopのパスを設定する必要があります。これにより、コマンドプロンプトからJDKとHadoopのコマンドを実行できるようになります。次に、 hostsファイル にlocalhostのエントリを追加する必要があります。これにより、Hadoopがlocalhostを認識できるようになります。最後に、 Hadoopの設定ファイル (hadoop-env.cmd、core-site.xml、hdfs-site.xml、mapred-site.xml) を編集して、Hadoopの動作を設定する必要があります。
Windows 7でHadoopの分散処理システムを構築するにはどうすればいいですか?
Windows 7でHadoopの分散処理システムを構築するには、まず Hadoopのクラスタモード を設定する必要があります。これにより、複数のノードでHadoopを動作させることができます。次に、 HDFS (Hadoop Distributed File System) を設定する必要があります。これにより、データを分散して保存できるようになります。最後に、 MapReduce を設定する必要があります。これにより、データを分散して処理できるようになります。
Windows 7でHadoopを動かす際に発生するエラーはどうすればいいですか?
Windows 7でHadoopを動かす際に発生するエラーは、 ログファイル を確認することで解決できることが多いです。Hadoopは、エラー発生時にログファイルにエラー情報を出力します。ログファイルを確認することで、エラーの原因を特定し、解決策を講じることができます。さらに、 オンラインコミュニティ や Hadoopの公式ドキュメント を参照することで、エラーの解決策を探すことができます。
コメントを残す
コメントを投稿するにはログインしてください。
関連ブログ記事